Metadata Governance for Educational Publishers
Metadata determines how content is discovered, classified, distributed and reused across platforms. This page explains what metadata governance means in practice, where publishing workflows tend to break down, and what it takes to embed governance at scale.
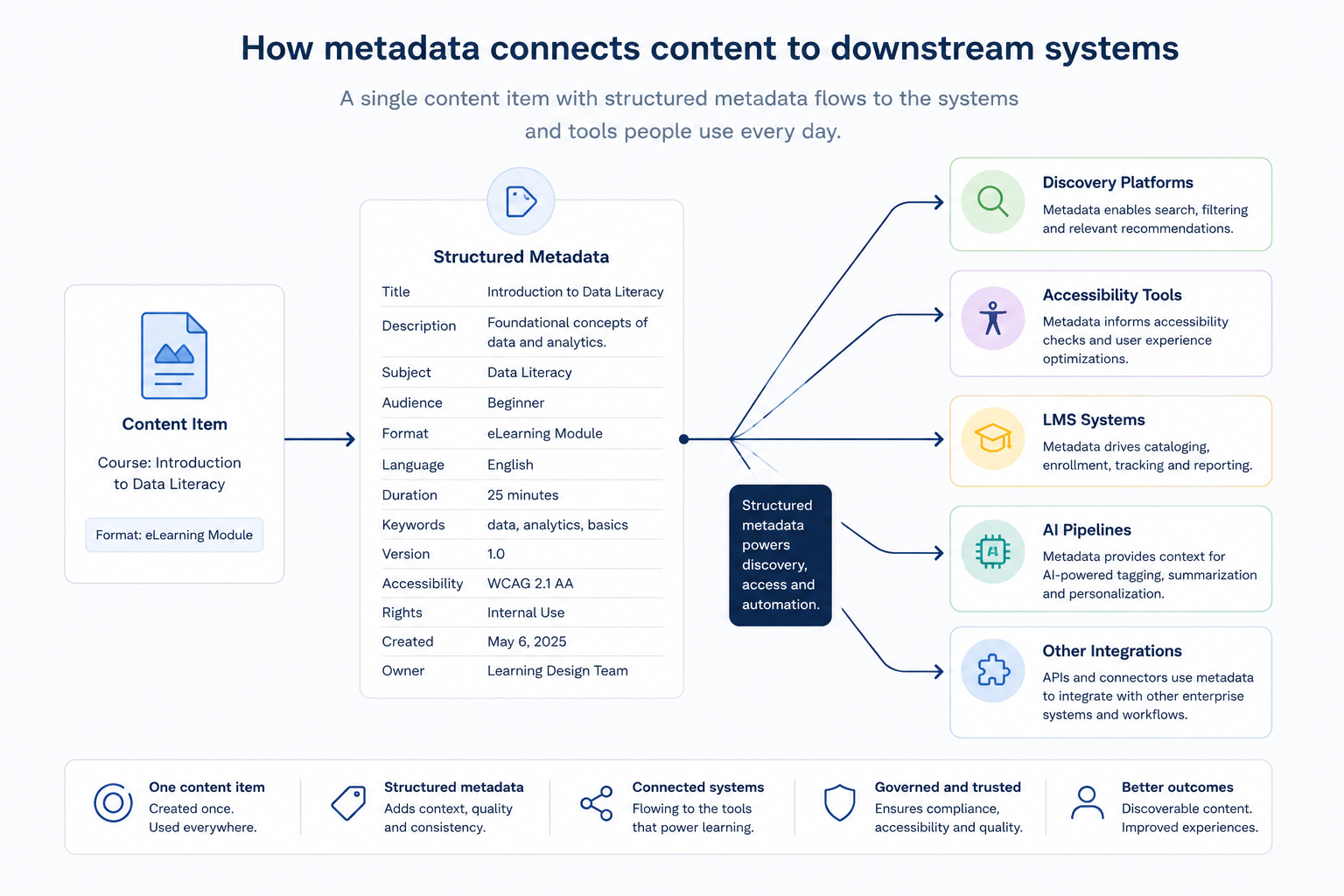
Metadata is not a background concern. It is the layer that connects content to every system that depends on it: discovery platforms, learning environments, distribution partners, accessibility tools and AI-driven pipelines.
Yet in many publishing organisations, metadata is still treated as a secondary task, applied inconsistently and often too late in the production process. As content ecosystems become more complex, that approach compounds into real operational and commercial risk.
Key point
Metadata governance is not about adding more fields or enforcing rigid standards. It is about creating the conditions for metadata to be accurate, consistent and usable at scale.
What is metadata governance?
Metadata governance is the framework of standards, rules and processes that ensure metadata is created, maintained and applied consistently across a publishing organisation.
Effective governance defines:
- What metadata is required for each content type
- How it should be structured and formatted
- When it should be created or updated
- Who is responsible for maintaining it
When these questions are answered and embedded into workflow, metadata stops being a by-product of publishing and becomes a reliable, structured asset.
Why metadata governance matters now
Publishing workflows have changed. Content is no longer produced for a single format or channel. It is reused across digital platforms, learning environments, distribution partners and AI-driven systems.
Without strong governance, the consequences compound across the entire content lifecycle. Metadata issues that once stayed contained within a single workflow now propagate across every system that depends on the content.
Discovery
Inconsistent metadata makes content harder to find, both internally for production teams and externally for learners.
Accessibility
Accessibility requirements depend on structured, complete metadata. Gaps create compliance risk that is costly to remediate.
Standards alignment
Maintaining accurate curriculum alignment at scale is not possible without consistent, well-governed metadata foundations.
AI reliability
AI outputs are only as good as their inputs. Poorly structured metadata produces unreliable results in AI and RAG-based systems.
Where governance breaks down in practice
Many publishers recognise the importance of metadata, but struggle to operationalise it. These are governance problems as much as tooling problems, and they tend to accumulate over time.
Inconsistent standards across teams
Different teams apply different conventions, leading to fragmented datasets that cannot be reconciled at scale. Without a shared standard, every integration becomes a remediation project.
Metadata handled inconsistently across stages
Different teams engage with metadata at different points in the production process. When it reaches some stages too late, context is already lost and correction becomes expensive. Without a shared approach to timing, inconsistencies compound across the workflow.
Manual processes at volume
Large volumes of metadata created or updated by hand increases error rates and slows production throughput. Manual processes also make it difficult to apply governance consistently.
Unclear ownership over time
Without clear responsibility for maintaining metadata quality, issues accumulate without resolution. Governance that relies on individual effort rather than embedded process is fragile.
Limited visibility and auditability
Without tooling, it is difficult to validate, report on or systematically improve metadata quality across a large content library. Problems remain invisible until they cause downstream failures.
Inherited metadata debt
Years of inconsistent practice create a backlog that cannot be addressed through manual effort alone. Legacy debt also makes it harder to implement new governance standards without disruption.
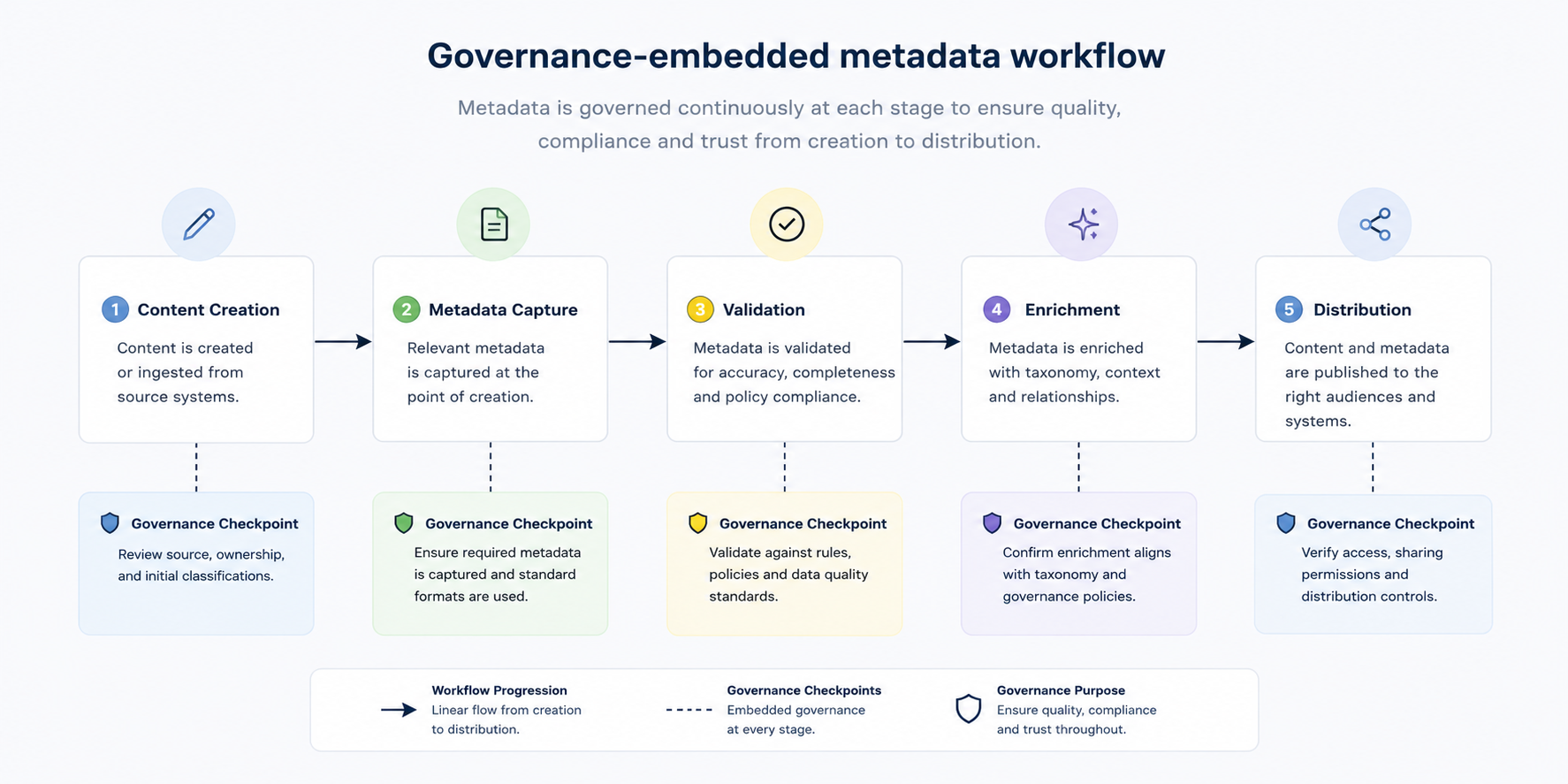
Content creation
Metadata requirements defined before production begins
Metadata capture
Structured fields applied as content is authored
Continuous validation
Quality checked throughout production, not only at delivery
Enrichment
AI-assisted tagging and classification at scale
Distribution
Structured, validated metadata delivered to downstream systems
Embedding governance into the workflow
Effective metadata governance is not enforced at the end of production. It is built into the workflow from the start. When governance is embedded, metadata becomes part of how content is created, not something added afterwards.
This means metadata requirements are defined at content creation stage, structures and schemas are applied consistently across content types, and validation happens continuously rather than as a final check. Updates are tracked and versioned over time, and responsibility is clearly assigned across teams at each stage.
When metadata is consistent at this level, content also becomes genuinely queryable. Production teams can identify gaps in subject coverage, surface underused content for repurposing, and direct editorial effort toward areas that actually need it. Rather than editors spending time on manual classification, that work shifts to AI, and editorial expertise is reserved for review, judgement and quality.
When governance is embedded at this level, the cost of maintaining quality drops significantly, and the risk of downstream failure drops with it.
AI handles
Extraction from content at scale, classification suggestions, gap identification, and enrichment of legacy content libraries.
Governance defines
The standards, taxonomies and validation rules that AI outputs are measured against. What correct looks like.
Experts validate
Editorial and subject matter expertise reviews, refines and approves outputs before they enter the production pipeline.
The role of AI in metadata governance
AI changes what is possible in metadata operations, but it does not remove the need for governance. Without defined standards and oversight, AI will replicate and amplify existing inconsistencies at scale.
The most effective implementations treat AI as an acceleration layer within a governed process. AI handles the volume and speed that manual workflows cannot sustain. Governance defines what correct outputs look like. Editorial and subject matter experts validate and refine before metadata enters production.
This is why human-in-the-loop models are critical. Removing the human from the loop does not reduce the governance requirement; it simply makes failure harder to detect.
Standards alignment
Accurate classification against curriculum frameworks
Accessibility compliance
Structured metadata supports auditable compliance workflows
Discovery and reuse
Content that can be found, filtered and repurposed reliably
Platform distribution
Consistent metadata delivered across partners and integrations
AI and RAG systems
Reliable inputs produce reliable outputs at scale
Metadata governance as infrastructure
In modern publishing, metadata governance functions as infrastructure. Like any infrastructure, its value is not immediately visible, but its absence is immediately felt.
When governance is in place, it supports standards alignment and classification, accessibility compliance, content discoverability and reuse, reliable distribution across platforms and partners, and AI and RAG-based systems that depend on structured, consistent inputs.
Without it, these capabilities remain fragmented and difficult to scale. With it, content operations become structured, consistent and significantly more efficient.

Syllabyte Platform
Metadata Management
Define, enforce and automate metadata governance across your content library, with continuous validation and full traceability.
How technology supports metadata governance at scale
Managing metadata governance manually becomes unsustainable as catalogue size grows and content types multiply. Technology platforms address this by embedding governance checkpoints directly into production workflows, automating extraction and enrichment, and providing the visibility needed to audit and improve quality over time.
Syllabyte embeds metadata governance into the workflow, ensuring content is structured early enough to support accessibility, discovery and reliable AI use, rather than relying on costly downstream fixes.
Publishers working with Syllabyte are able to address legacy metadata debt at scale while establishing governance frameworks that prevent further accumulation.
Further reading
Guide
Standards alignment for educational publishers
How to maintain accurate, scalable curriculum alignment across large content libraries.
Read moreGuide
Accessibility compliance in educational publishing
Embedding accessibility requirements into production workflows from the start, not as a remediation step.
Read moreGuide
RAG pipelines for educational content
Why structured, governed content produces better outcomes in retrieval-augmented generation systems.
Read moreReady to discuss your metadata workflow?
We work with editorial and content operations teams to understand how governance fits into your existing production process.